Indexiert, obwohl durch robots.txt blockiert — alles, was Sie wissen müssen
Erfahren Sie, wie Sie Robots.txt-Optimierung für bessere SEO-Performance einsetzen. Wenn Google Seiten Ihrer Website indexiert, aber nicht crawlen kann, erhalten Sie in der Google Search Console (GSC) die Meldung „Indexiert, obwohl durch robots.txt blockiert”.
Google sieht diese Seiten zwar — zeigt sie aber nicht in den Suchergebnissen für ihre Ziel-Keywords.
Wenn das passiert, verpassen Sie die Chance auf organischen Traffic für diese Seiten.
Besonders kritisch ist das bei Seiten, die monatlich Tausende organische Besucher generieren — und plötzlich auf dieses Problem stoßen.
An diesem Punkt haben Sie wahrscheinlich viele Fragen zur Meldung. Warum haben Sie sie erhalten? Wie ist es dazu gekommen? Und vor allem: Wie beheben Sie das Problem und holen den Traffic zurück, wenn es eine bereits gut rankende Seite betroffen hat?
Dieser Beitrag beantwortet all diese Fragen — und zeigt, wie Sie das Problem auf Ihrer Site künftig vermeiden.
So erkennen Sie, ob Ihre Site betroffen ist
Normalerweise erhalten Sie eine E-Mail von Google mit einem „Index Coverage Issue” auf Ihrer Site. So sieht die E-Mail aus:
Die E-Mail nennt nicht die genauen betroffenen Seiten oder URLs. Sie müssen sich in die Google Search Console einloggen, um das selbst herauszufinden.
Auch wenn Sie keine E-Mail bekommen haben, lohnt sich ein Blick — damit Ihre Site in Topform bleibt.
Nach dem GSC-Login: Index Coverage Report öffnen über Coverage unter Index. Auf der nächsten Seite nach unten scrollen, um die von GSC gemeldeten Probleme zu sehen.
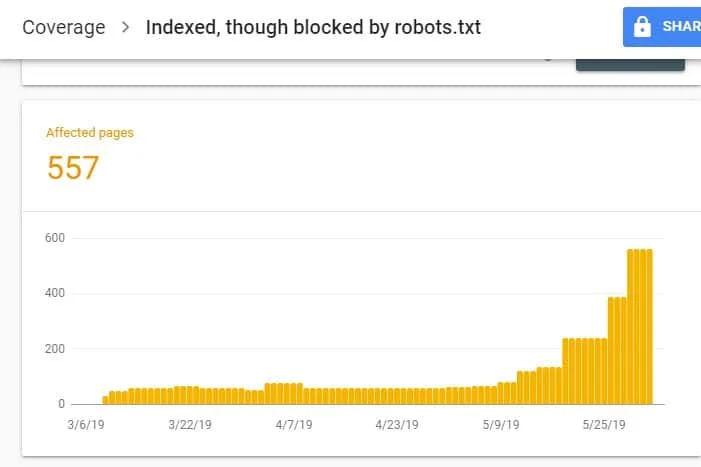
„Indexiert, obwohl durch robots.txt blockiert” wird unter „Valid with warning” gelistet. Heißt: Mit der URL ist nichts grundsätzlich falsch — Suchmaschinen zeigen die Seiten aber nicht in den Suchergebnissen.
Warum hat Ihre Site dieses Problem (und wie beheben)?
Bevor Sie an Lösungen denken, müssen Sie wissen, welche Seiten indexiert werden müssen und in den Suchergebnissen erscheinen sollen.
Es ist möglich, dass die in der GSC gemeldeten URLs gar nicht für organischen Traffic gedacht sind — etwa Landingpages für Paid-Ads-Kampagnen. In dem Fall lohnt sich der Aufwand vielleicht nicht.
Hier die Gründe, warum manche Ihrer Seiten dieses Problem haben — und ob Sie sie beheben sollten:
Disallow-Regel in robots.txt und Noindex-Meta-Tag im Page-HTML
Der häufigste Grund: Sie oder jemand, der Ihre Site verwaltet, hat die Disallow-Regel für eine bestimmte URL in der robots.txt aktiviert und gleichzeitig den Noindex-Meta-Tag auf derselben URL eingebaut.
Site-Betreiber nutzen robots.txt, um Suchmaschinen-Crawlern mitzuteilen, wie sie URLs behandeln sollen. In dem Fall haben Sie die Disallow-Regel für Seiten und Ordner Ihrer Site in der robots.txt eingetragen.
So könnte Ihre robots.txt aussehen:
User-agent: * Disallow: /
Im Beispiel oben verhindert diese Codezeile, dass alle Web-Crawler (*) Seiten Ihrer Site crawlen (Disallow) — inklusive der Startseite (/). Resultat: Keine Suchmaschine crawlt oder indexiert Ihre Site-Seiten.
Sie können die robots.txt editieren, um spezifische Web-Crawler (Googlebot, msnbot, magpie-crawler usw.) anzusprechen — und festzulegen, welche Seiten die Crawler nicht anfassen sollen (/page1, /page2, /page3 usw.).
Wenn Sie keinen Root-Zugriff auf Ihren Server haben, können Sie Suchmaschinen-Bots vom Indexieren über den Noindex-Tag abhalten.
Die Methode hat denselben Effekt wie die Disallow-Regel — statt aber Seiten und Ordner in einer robots.txt aufzulisten, setzen Sie das Noindex-Meta-Tag auf jede einzelne Seite, die nicht in den Suchergebnissen erscheinen soll.
Das ist deutlich aufwendiger als die robots.txt — gibt Ihnen aber granulare Kontrolle, welche URL Sie blocken. Geringere Fehlermarge.
Fix: Das Problem in der GSC entsteht, wenn Seiten Ihrer Site sowohl eine Disallow-Regel in robots.txt als auch einen Noindex-Tag haben.
Damit Suchmaschinen wissen, ob sie eine Seite indexieren sollen, müssen sie die Seite crawlen können. Verhindern Sie das durch die robots.txt, weiß Google nicht, was es mit der Seite anfangen soll.
Indem robots.txt und Noindex-Tag sich ergänzen — nicht widersprechen — bekommt Ihre Site klarere, direktere Regeln für Suchmaschinen-Bots.
Dafür müssen Sie Ihre robots.txt editieren. Für WordPress-Betreiber sind SEO-Plugins mit robots.txt-Editor wie Yoast SEO oder Rank Math am bequemsten.
![]()
Falls die robots.txt bei Ihnen nicht beschreibbar ist, kontaktieren Sie Ihren Hosting-Provider, um Berechtigungen anzupassen.
Eine Alternative: per FTP-Client oder dem File Manager Ihres Hosters einloggen. Bei Entwicklern beliebt — sie haben volle Kontrolle.
Falsches URL-Format
URLs Ihrer Site, die nicht im strengen Sinn „Seiten” sind, können die Meldung „Indexiert, obwohl durch robots.txt blockiert” erhalten.
Beispiel: https://example.com?s=what+is+seo ist eine Seite, die Suchergebnisse für die Anfrage „what is seo” zeigt. Das ist bei WordPress-Sites mit aktivierter Site-weiter Suche üblich.
Fix: Normalerweise besteht kein Handlungsbedarf — vorausgesetzt, die URL ist harmlos und beeinflusst Ihren Suchtraffic nicht spürbar.
Seiten, die Sie nicht indexieren wollen, haben interne Links
Selbst mit Noindex-Tag auf der Seite, die Sie nicht indexieren wollen, kann Google das Tag als Vorschlag — nicht als Regel — werten. Das ist klar erkennbar, wenn Sie auf Seiten mit Noindex-Direktive oder Disallow-Regel von Seiten verlinken, die Suchmaschinen crawlen und indexieren.
Folge: Sie sehen diese Seiten in den SERPs, obwohl Sie das nicht wollen.
Fix: Entfernen Sie Links, die auf diese Seite zeigen, und leiten Sie sie auf eine ähnliche Seite um.
Identifizieren Sie die internen Links über ein SEO-Audit mit Tools wie Screaming Frog (kostenlos bis 500 URLs) oder Ahrefs Webmaster Tools (eine deutlich bessere kostenlose Alternative).
Mit Ahrefs gehen Sie nach dem Audit zu Reports > Internal Pages. Finden Sie die für Web-Crawler geblockten und mit Noindex versehenen Seiten — und sehen Sie in der „No. of Inlinks”-Spalte, welche Seiten auf sie verlinken.
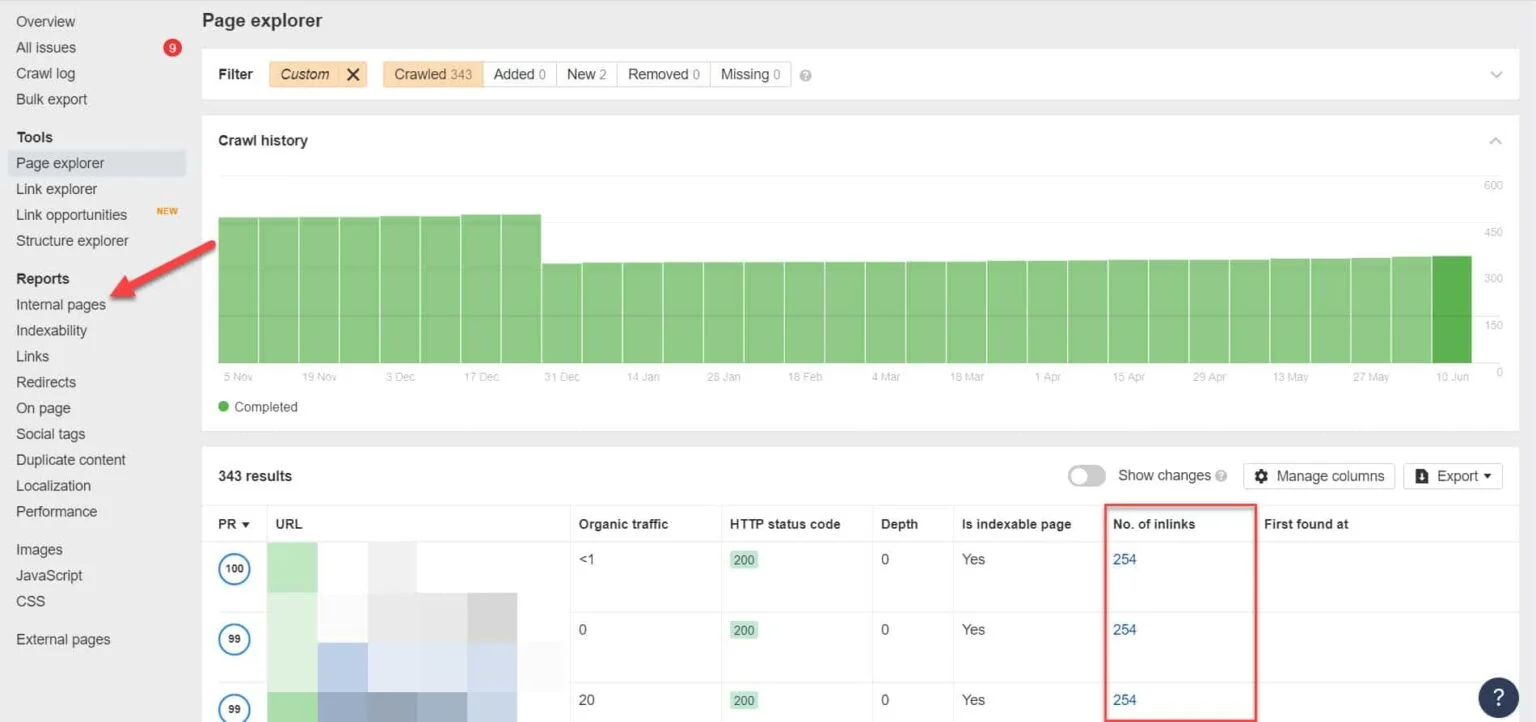
Von hier editieren Sie die Links einzeln — oder ersetzen sie durch einen Link zu Ihrer Seite mit Noindex-Tag.
Auf eine Redirect-Kette zeigen
Wenn ein Link Ihrer Site auf einen endlosen Redirect-Stream zeigt, gibt der Googlebot irgendwann auf, bevor er die eigentliche URL erreicht.
Solche Redirect-Ketten können auch Duplicate-Content-Probleme verursachen — und größere SEO-Probleme nach sich ziehen. Lösen lässt sich das nur, indem Sie Ihre bevorzugte, kanonische Seite mit dem Canonical-Tag markieren — damit Google weiß, welche der vielen Seiten gecrawlt und indexiert werden soll.
Bedenken Sie zudem: Ein Redirect-Link statt der kanonischen Seite verbraucht Ihr Crawl-Budget. Zeigen Redirect-Links auf weitere Redirects, geht Ihr Crawl-Budget für unwichtige Seiten drauf. Bis Google an Ihre wichtigen Seiten kommt, kann es sie nicht mehr ordentlich crawlen und indexieren.
Fix: Eliminieren Sie Redirect-Links auf Ihrer Site — und verlinken Sie stattdessen direkt auf die kanonische Seite.
Mit Ahrefs Webmaster Tools sehen Sie Ihre Redirect-Links unter Tools > Link Explorer. Filtern Sie die Ergebnisse, sodass nur Redirect-Links Ihrer Site angezeigt werden.
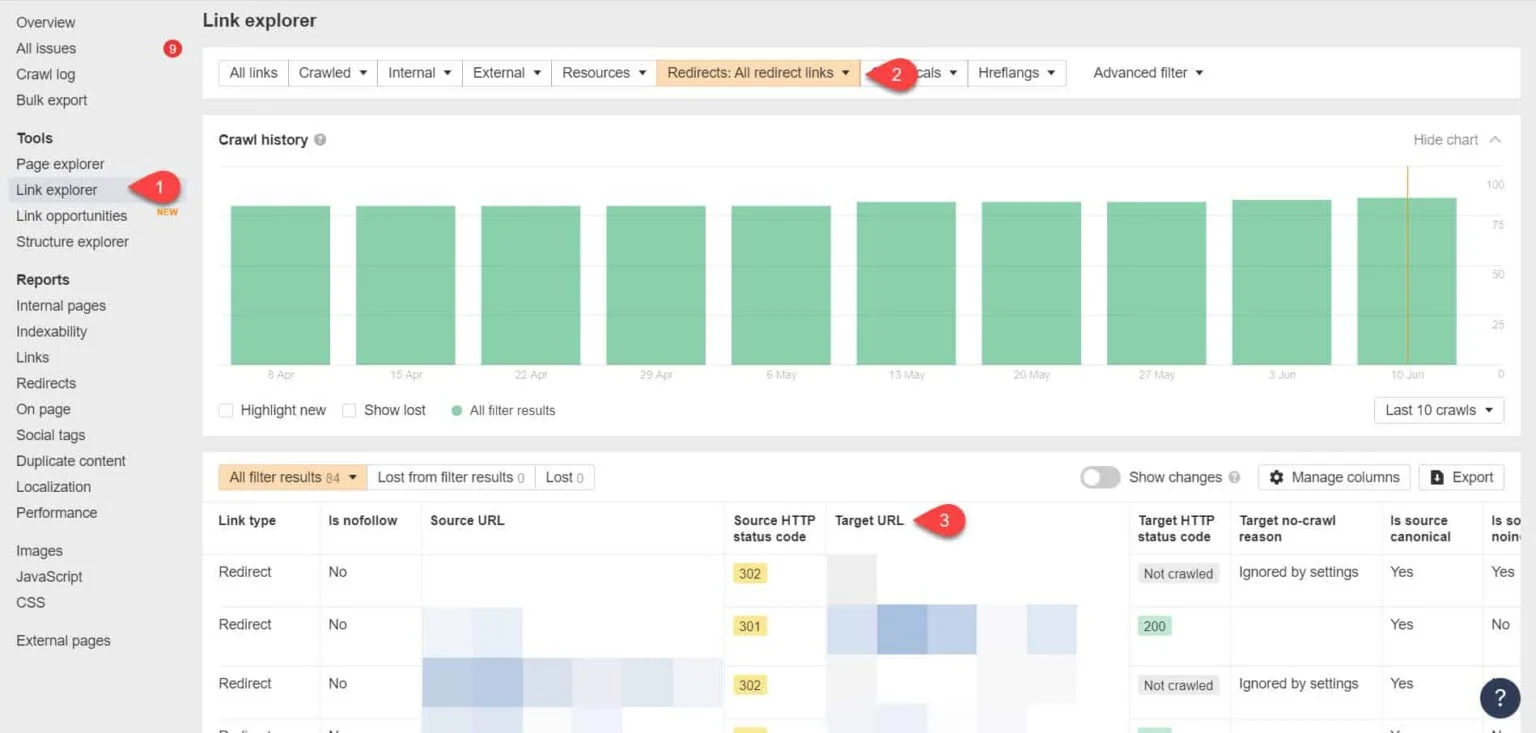
Identifizieren Sie aus den Ergebnissen die endlosen Redirect-Ketten — und brechen Sie sie, indem Sie für jede Seite, die auf den Redirect zeigt, die korrekte Zielseite finden.
Was nach dem Fix zu tun ist
Sobald Sie die Lösungen für wichtige Seiten mit „Indexiert, obwohl durch robots.txt blockiert”-Problem angewandt haben, müssen Sie die Änderungen verifizieren — damit die Google Search Console sie als „resolved” markiert.
Zurück im Index Coverage Report in der GSC: Klicken Sie auf die behobenen Links mit diesem Problem. Im nächsten Screen klicken Sie auf den „Validate Fix”-Button.
Damit fordern Sie Google auf zu prüfen, ob das Problem nicht mehr besteht.
Fazit
Anders als andere von der Google Search Console aufgedeckte Probleme wirkt „Indexiert, obwohl durch robots.txt blockiert” wie ein Tropfen auf dem heißen Stein. Diese Tropfen können sich aber zu einer Flut summieren — und Ihre gesamte Site daran hindern, organischen Traffic zu generieren.
Wenn Sie den oben genannten Guidelines für Ihre wichtigsten Seiten folgen, verhindern Sie, dass Ihre Website wertvollen Traffic verliert — und optimieren sie für sauberes Crawling und Indexieren durch Google.