Découvrez comment vous pouvez appliquer l’optimisation Robots.txt pour de meilleures performances SEO. Si vous avez des pages de votre site Web que Google a indexées, mais que vous ne pouvez pas explorer, vous recevrez un message « Indexées, bien que bloquées par Robots.txt » sur votre Google Search Console (GSC).
Bien que Google puisse afficher ces pages, il ne les affichera pas dans le cadre des pages de résultats des moteurs de recherche pour leurs mots-clés cibles.
Si tel est le cas, vous manquerez l’opportunité d’obtenir du trafic organique pour ces pages.
Ceci est particulièrement crucial pour les pages générant des milliers de visiteurs organiques mensuels qui rencontrent ce problème.
À ce stade, vous avez probablement beaucoup de questions sur ce message d’erreur. Pourquoi l’avez-vous reçu ? Comment cela s’est-il passé ? Et, plus important encore, comment pouvez-vous y remédier et récupérer le trafic si cela s’est produit sur une page qui était déjà bien classée.
Cet article répondra à toutes ces questions et vous montrera comment éviter que ce problème ne se reproduise sur votre site.
Comment savoir si votre site rencontre ce problème
Normalement, vous devriez recevoir un e-mail de Google vous informant d’un « problème de couverture d’index » sur votre site. Voici à quoi ressemble l’e-mail :
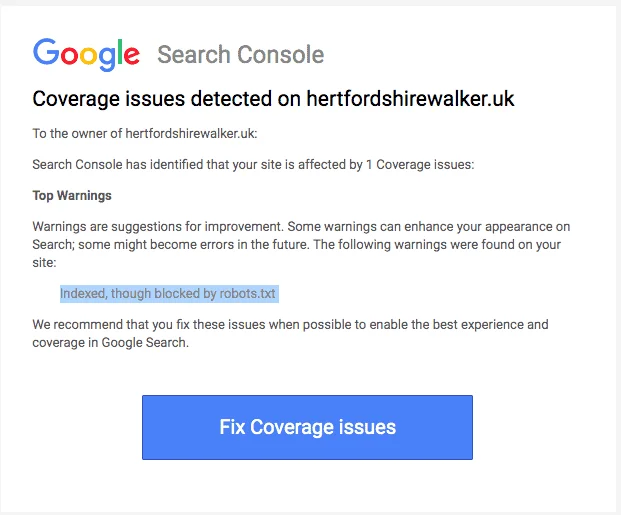
L’e-mail ne précise pas quelles sont les pages ou l’URL exactes concernées. Vous devrez vous connecter à votre Google Search Console pour le savoir vous-même.
Si vous n’avez pas reçu d’e-mail, il est préférable de le voir par vous-même pour vous assurer que votre site est en parfait état.
Une fois connecté à GSC, accédez au rapport sur la couverture de l’indice en cliquant sur Couverture sous Index. Ensuite, sur la page suivante, faites défiler vers le bas pour voir les problèmes signalés par GSC.
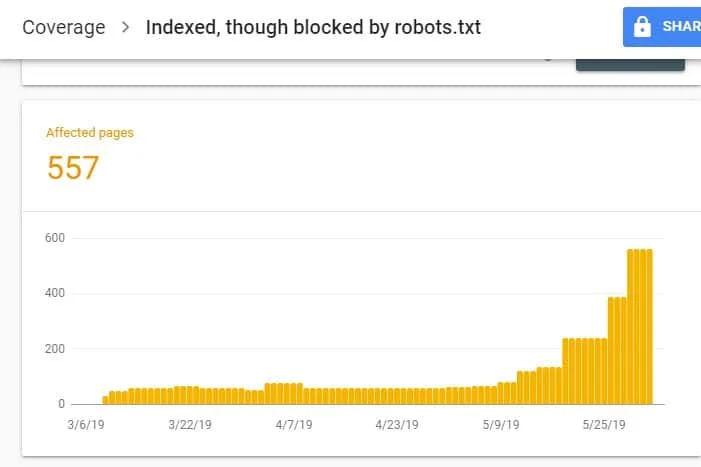
L’option « Indexé, bien que bloqué par robots.txt » est étiqueté sous « Valide avec avertissement ». Cela signifie qu’il n’y a rien de mal avec l’URL en soi, mais que les moteurs de recherche n’afficheront pas la ou les pages dans les résultats des moteurs de recherche.
Pourquoi votre site rencontre-t-il ce problème (et comment y remédier) ?
Avant de commencer à réfléchir à une solution, vous devez d’abord savoir quelles pages doivent être indexées etdoivent apparaître dans les résultats de recherche.
Il est possible que les URL que vous voyez sur GSC avec le problème « Indexé, bien que bloqué par robots.txt » ne soient pas destinés à générer du trafic organique vers votre site. Par exemple, les pages de destination de vos campagnes publicitaires payantes. Par conséquent, réparer les pages peut ne pas valoir votre temps et vos efforts.
Vous trouverez ci-dessous les raisons pour lesquelles certaines de vos pages rencontrent ce problème et si vous devez ou non les résoudre :
Interdire la règle sur votre balise méta Robots.txt etnoindex dans le code HTML de la page
La raison la plus courante pour laquelle ce problème se produit est lorsque vous ou quelqu’un qui gère votre site activez la règle Interdire pour cette URL spécifique sur le robots.txt de votre site et ajoutez la balise méta noindex sur la même URL.
Tout d’abord, les propriétaires de sites utilisent robots.txt pour informer les robots des moteurs de recherche sur la façon de traiter les URL de votre site. Dans ce cas, vous avez ajouté la règle d’interdiction sur les pages et les dossiers de votre site dans le robots.txt de votre site Web.
Voici ce que vous pouvez voir lorsque vous ouvrez le fichier robots.txt de votre site :
User-agent : * Interdire : /
Dans l’exemple ci-dessus, cette ligne de code empêche tous les robots d’exploration (*) d’explorer les pages de votre site (Interdire d’inclure) votre page d’accueil (/). Par conséquent, tous les moteurs de recherche n’exploreront ni n’indexeront les pages de votre site.
Vous pouvez modifier robots.txt pour isoler les robots d’exploration (Googlebot, msnbot, magpie-crawler, etc.) et spécifier la ou les pages que vous ne souhaitez pas qu’ils touchent (/page1, /page2, /page3, etc.).
Toutefois, si vous ne disposez pas d’un accès root à votre serveur, vous pouvez empêcher les robots des moteurs de recherche d’indexer les pages de votre site à l’aide de la balise noindex.
Cette méthode a le même effet que la règle d’interdiction sur robots.txt. Cependant, au lieu de répertorier les différentes pages et dossiers de votre site dans un fichier robots.txt que vous souhaitez empêcher d’apparaître sur les SERP, vous devez entrer la balise meta noindex sur chaque page de votre site que vous ne souhaitez pas voir apparaître dans les résultats de recherche.
Il s’agit d’un processus beaucoup plus long que la méthode précédente, mais il vous donne un contrôle plus granulaire sur l’URL à bloquer. Cela signifie également qu’il y a une marge d’erreur plus faible de votre part.
Réparer: Encore une fois, le problème dans GSC se pose lorsque les pages de votre site ont une règle d’interdiction sur robots.txt fichier et une balise noindex.
Pour que les moteurs de recherche sachent s’ils doivent indexer une page ou non, ils doivent être capables de l’explorer à partir de votre site. Mais si vous empêchez les moteurs de recherche de le faire via votre robots.txt, il ne saura pas quoi faire de cette page.
En utilisant robots.txt et la balise noindex pour se compléter et non se concurrencer, votre site aura des règles beaucoup plus claires et plus directes à suivre pour les robots des moteurs de recherche lors du traitement de ses pages.
Pour ce faire, vous devez modifier votre fichier robots.txt. Pour les propriétaires de sites WordPress, l’utilisation de plugins SEO avec un éditeur de robots.txt comme Yoast SEO ou Rank Math est la plus pratique.
![]()
Si le robots.txt n’est pas accessible en écriture de votre côté, vous devez contacter votre fournisseur d’hébergement pour apporter des modifications d’autorisation à vos fichiers et dossiers.
Une autre façon consiste à se connecter à votre client FTP ou au gestionnaire de fichiers de votre fournisseur d’hébergement. C’est la méthode préférée des développeurs car ils ont un contrôle total sur la façon de modifier le fichier, entre autres choses.
Mauvais format d’URL
Les URL de votre site qui ne sont pas vraiment des « pages » au sens strict du terme peuvent recevoir le message « Indexé, bien que bloqué par robots.txt ».
Par exemple, https ://example.com ?s=what+is+seo est une page d’un site qui affiche les résultats de recherche pour la requête « qu’est-ce que le référencement ». Cette URL est répandue sur les sites WordPress où la fonction de recherche est activée sur l’ensemble du site.
Réparer: Normalement, il n’est pas nécessaire d’aborder ce problème, en supposant que l’URL est inoffensive et n’affecte pas profondément votre trafic de recherche.
Les pages que vous ne souhaitez pas indexer ont des liens internes
Même si vous avez une balise noindex sur la page que vous ne souhaitez pas indexer, Google peut les traiter comme des suggestions plutôt que comme des règles. Cela est évident lorsque vous créez des liens vers des pages avec la directive noindex ou la règle disallow sur les pages de votre site que les moteurs de recherche explorent et indexent.
Par conséquent, vous pouvez voir ces pages apparaître sur les SERP même si vous ne le souhaitez pas.
Correction : Vous devez supprimer les liens pointant vers cette page particulière et les diriger vers une page similaire à la place.
Pour ce faire, vous devez identifier ses liens internes en effectuant un audit SEO à l’aide d’un outil comme Screaming Frog (gratuit pour les sites web avec 500 URLs) ou Ahrefs Webmaster Tools (une bien meilleure alternative gratuite) pour identifier quelles pages renvoient à vos pages bloquées.
À l’aide d’Ahrefs, accédez aux pages Rapports > internes après avoir exécuté un audit. Recherchez les pages que vous avez bloquées des robots d’exploration Web et noindexed et voyez quelles pages sont liées à celles-ci sur le Non. de la colonne Inlinks.
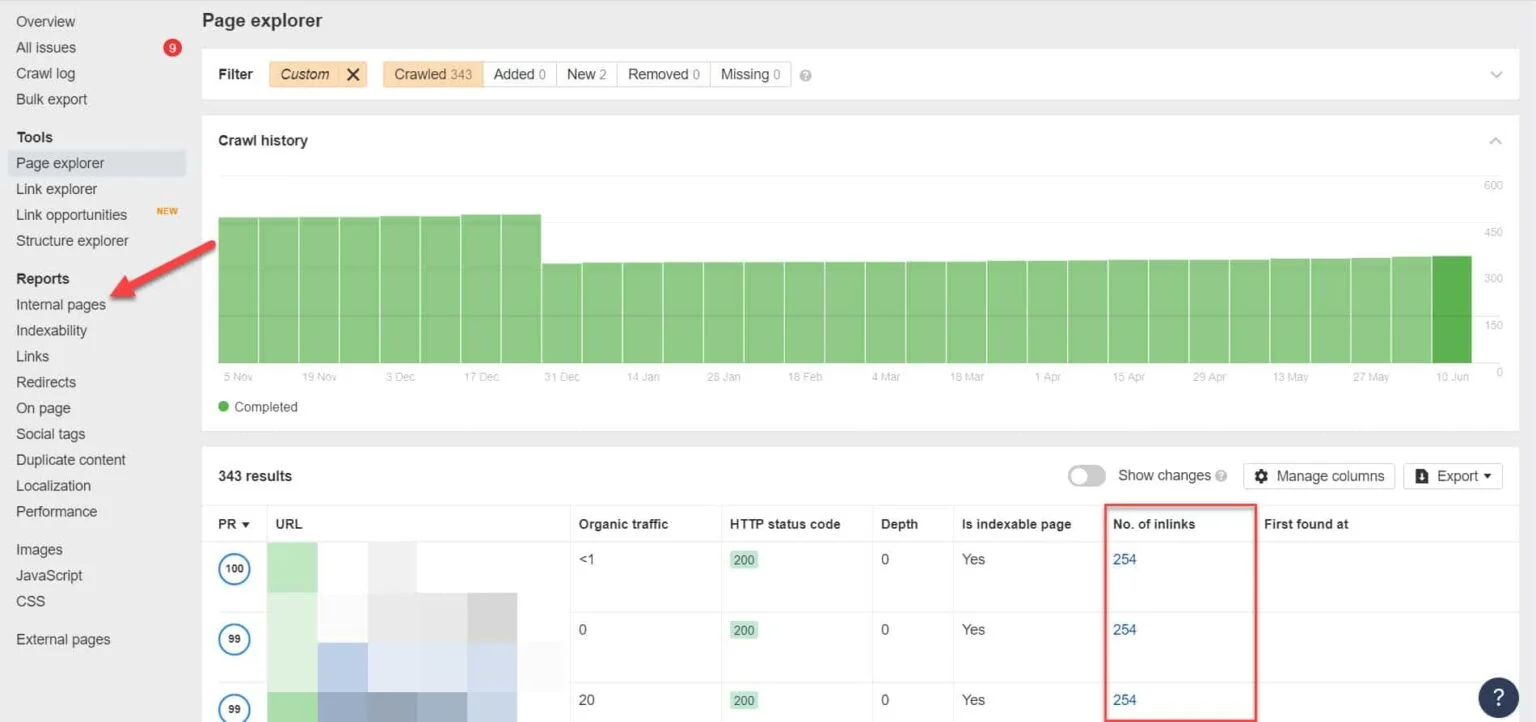
À partir de là, modifiez les liens de ces pages un par un. Ou vous pouvez les remplacer par un lien vers votre page avec une balise noindex.
Pointage vers une chaîne de redirection
Si un lien de votre site pointe vers un flux ininterrompu de redirections, Googlebot cessera de passer par chaque lien avant de trouver l’URL réelle de la page.
Ces chaînes de redirection pourraient également causer des problèmes de contenu dupliqué qui pourraient causer des problèmes de référencement plus importants sur toute la ligne. La seule façon de résoudre ce problème est d’identifier votre page préférée et canonique à l’aide de la balise canonique, afin que Google sache quelle page parmi tant d’autres il doit explorer et indexer.
Considérez également que le fait de créer un lien vers une redirection au lieu de la page canonique utilise votre budget de crawl. Si le lien de redirection pointe vers plusieurs redirections, vous ne pouvez pas utiliser votre budget d’exploration sur les pages qui comptent dans votre site. Au moment où il arrive aux pages les plus importantes, Google ne sera pas en mesure de les explorer et de les indexer correctement après un certain temps.
Réparer: Éliminez les liens de redirection de votre site et créez un lien vers la page canonique à la place.
En utilisant à nouveau les outils pour les webmasters d’Ahrefs, vous pouvez afficher vos liens de redirection sur la page Explorateur de liens d’outils > . Filtrez ensuite les résultats pour ne vous montrer que les liens de redirection dans votre site.
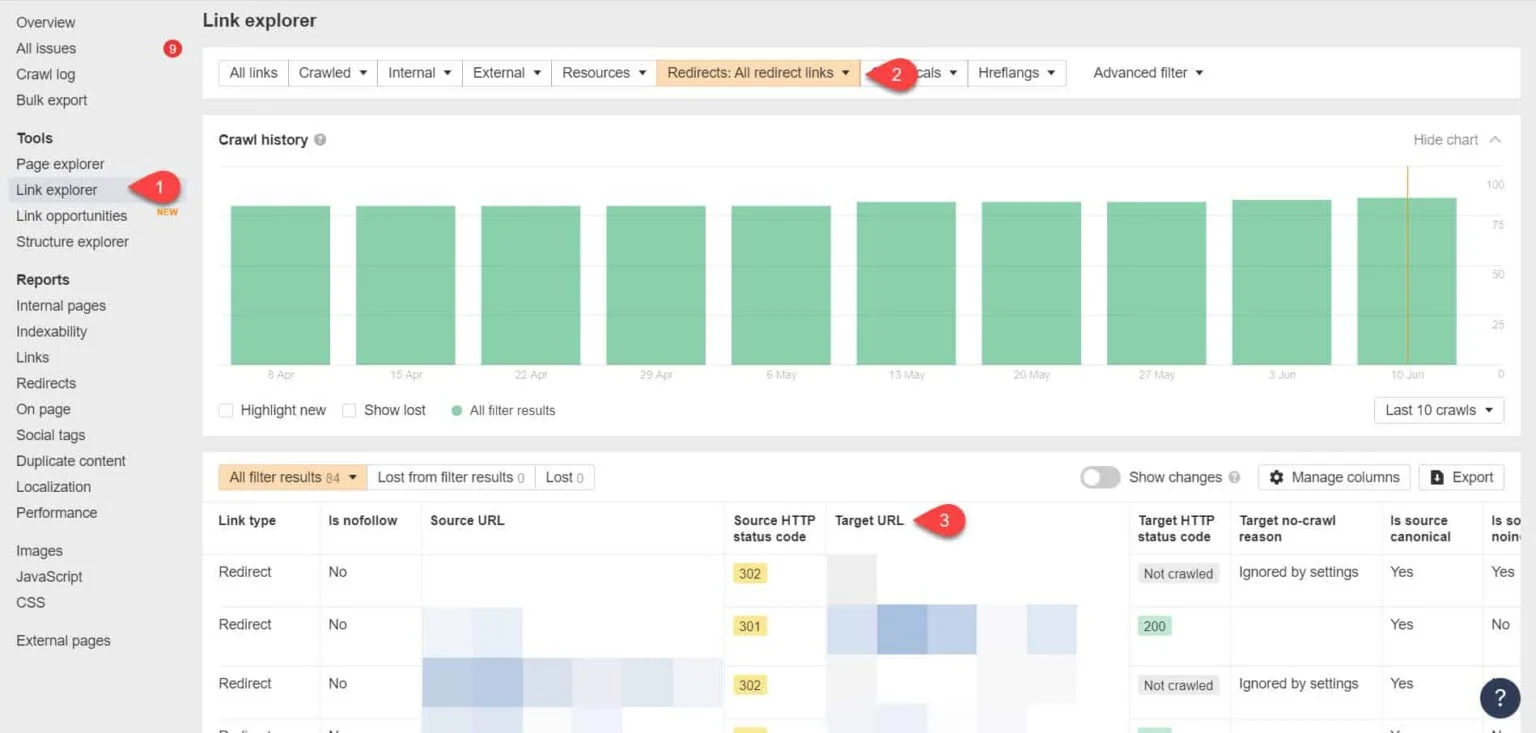
À partir des résultats, identifiez les liens qui forment une chaîne de redirection sans fin. Ensuite, brisez la chaîne en trouvant la bonne page à laquelle chaque page liée aux redirections doit être liée.
Que faire après avoir résolu ce problème
Une fois que vous avez mis en œuvre les solutions ci-dessus pour les pages importantes présentant le problème « Indexé, bien que bloqué par Robots.txt », vous devez vérifier les modifications afin que Google Search Console puisse les marquer comme résolues.
En revenant au rapport de couverture de l’indice dans GSC, cliquez sur les liens avec le problème que vous avez résolu. Sur l’écran suivant, cliquez sur le bouton Valider le correctif.
Cela demandera à Google de vérifier si la page ne présente plus le problème.
Conclusion
Contrairement à d’autres problèmes découverts par Google Search Console, « Indexé, bien que bloqué par robots.txt » peut sembler être une goutte d’eau dans l’océan. Cependant, ces baisses pourraient s’accumuler en un torrent de problèmes sur l’ensemble de votre site qui l’empêchera de générer du trafic organique.
En suivant les instructions ci-dessus sur la façon de résoudre le problème sur vos pages les plus importantes, vous pouvez empêcher votre site Web de perdre du trafic précieux en optimisant votre site Web pour que Google puisse l’explorer et l’indexer correctement.