Descubre cómo aplicar la optimización de Robots.txt para un mejor rendimiento SEO. Si tienes páginas en tu web que Google ha indexado pero no puede rastrear, recibirás un mensaje «indexado aunque bloqueado por Robots.txt» en tu Google Search Console (GSC).
Aunque Google pueda mostrarlas, no las mostrará como parte de las páginas de resultados de los motores de búsqueda para sus keywords objetivo.
Si es el caso, perderás la oportunidad de conseguir tráfico orgánico para esas páginas.
Eso es especialmente crucial para páginas que generan miles de visitantes orgánicos mensuales y tienen este problema.
A estas alturas probablemente tengas muchas preguntas sobre este mensaje de error. ¿Por qué lo has recibido? ¿Cómo ha pasado? Y, más importante, ¿cómo puedes solucionarlo y recuperar el tráfico si ha ocurrido en una página que ya posicionaba bien?
Este artículo responderá a todas esas preguntas y te mostrará cómo evitar que vuelva a ocurrir en tu sitio.
Cómo saber si tu sitio tiene este problema
Normalmente deberías recibir un email de Google informándote de un «problema de cobertura de índice» en tu sitio. Así es como se ve el email:
El email no especifica qué páginas o URL exactas están afectadas. Tendrás que iniciar sesión en tu Google Search Console para averiguarlo por ti mismo.
Si no has recibido un email, es mejor comprobarlo por tu cuenta para asegurarte de que tu sitio está en perfecto estado.
Una vez en GSC, ve al reporte de cobertura de índice haciendo clic en Cobertura bajo Índice. Luego, en la siguiente página, desplázate abajo para ver los problemas señalados por GSC.
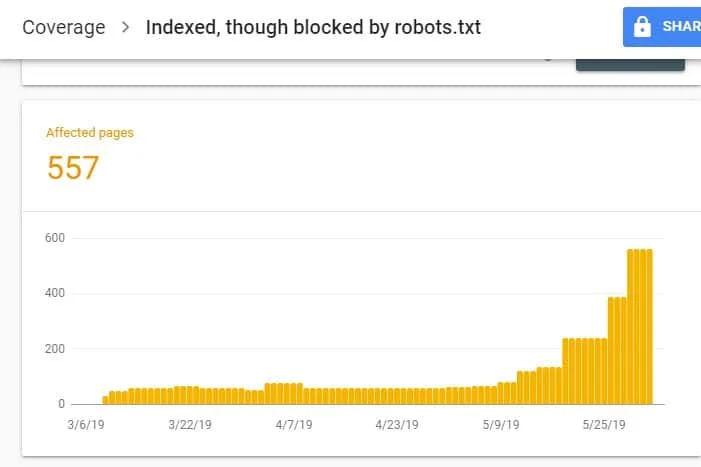
La opción «indexado aunque bloqueado por robots.txt» se etiqueta bajo «válido con aviso». Eso significa que no hay nada mal con la URL en sí, pero los motores de búsqueda no mostrarán la página o páginas en los resultados de búsqueda.
¿Por qué tu sitio tiene este problema (y cómo solucionarlo)?
Antes de empezar a pensar en una solución, debes saber primero qué páginas deberían indexarse y deberían aparecer en los resultados de búsqueda.
Es posible que las URL que ves en GSC con el problema «indexado aunque bloqueado por robots.txt» no estén destinadas a generar tráfico orgánico a tu sitio. Por ejemplo, las landing pages de tus campañas de anuncios de pago. Por tanto, arreglar las páginas puede no valer tu tiempo y esfuerzo.
Aquí tienes las razones por las que algunas de tus páginas tienen este problema y si deberías o no arreglarlas:
Regla Disallow en Robots.txt y meta tag noindex en el HTML de la página
La razón más común por la que ocurre este problema es cuando tú o alguien que gestiona tu sitio activa la regla Disallow para esa URL específica en el robots.txt de tu sitio y añade la meta tag noindex en la misma URL.
Primero, los propietarios de sitios usan robots.txt para informar a los bots de los motores de búsqueda sobre cómo tratar las URL de tu sitio. En este caso, has añadido la regla Disallow en las páginas y carpetas de tu sitio en el robots.txt de tu web.
Esto es lo que puedes ver cuando abres el archivo robots.txt de tu sitio:
User-agent: * Disallow: /
En el ejemplo anterior, esta línea de código impide que todos los bots de rastreo (*) rastreen las páginas de tu sitio (Disallow para incluir) tu página de inicio (/). Por tanto, ningún motor de búsqueda rastreará ni indexará las páginas de tu sitio.
Puedes modificar robots.txt para aislar los bots (Googlebot, msnbot, magpie-crawler, etc.) y especificar la página o páginas que no quieres que toquen (/pagina1, /pagina2, /pagina3, etc.).
Sin embargo, si no tienes acceso root a tu servidor, puedes impedir que los bots indexen las páginas de tu sitio con la etiqueta noindex.
Este método tiene el mismo efecto que la regla Disallow en robots.txt. Sin embargo, en vez de listar las distintas páginas y carpetas de tu sitio en un archivo robots.txt que quieres evitar que aparezcan en las SERP, tienes que introducir la meta tag noindex en cada página de tu sitio que no quieras ver en los resultados de búsqueda.
Es un proceso mucho más largo que el método anterior, pero te da un control más granular sobre qué URL bloquear. También significa que hay un menor margen de error por tu parte.
Arreglo: de nuevo, el problema en GSC surge cuando las páginas de tu sitio tienen una regla Disallow en el archivo robots.txt y una etiqueta noindex.
Para que los motores de búsqueda sepan si deben indexar una página o no, necesitan poder rastrearla desde tu sitio. Pero si impides a los motores de búsqueda hacerlo a través de tu robots.txt, no sabrán qué hacer con esa página.
Usando robots.txt y la etiqueta noindex para complementarse y no competir, tu sitio tendrá reglas mucho más claras y directas que seguir para los bots al procesar sus páginas.
Para eso, tienes que modificar tu archivo robots.txt. Para propietarios de sitios WordPress, usar plugins SEO con un editor de robots.txt como Yoast SEO o Rank Math es lo más práctico.
![]()
Si el robots.txt no es escribible por tu parte, tienes que contactar con tu proveedor de hosting para hacer cambios de permisos en tus archivos y carpetas.
Otra forma es iniciar sesión en tu cliente FTP o en el gestor de archivos de tu proveedor de hosting. Es el método preferido por los desarrolladores porque tienen control total sobre cómo modificar el archivo, entre otras cosas.
Formato de URL incorrecto
Las URL de tu sitio que en realidad no son «páginas» en sentido estricto pueden recibir el mensaje «indexado aunque bloqueado por robots.txt».
Por ejemplo, https://example.com?s=que+es+seo es una página de un sitio que muestra los resultados de búsqueda para la consulta «qué es seo». Esa URL es frecuente en sitios WordPress donde la función de búsqueda está activada en toda la web.
Arreglo: normalmente no hace falta abordar este problema, asumiendo que la URL es inofensiva y no afecta gravemente a tu tráfico de búsqueda.
Las páginas que no quieres indexar tienen enlaces internos
Aunque tengas una etiqueta noindex en la página que no quieres indexar, Google puede tratarlas como sugerencias en lugar de reglas. Eso es evidente cuando creas enlaces a páginas con la directiva noindex o la regla Disallow desde páginas de tu sitio que los motores de búsqueda sí rastrean e indexan.
Por tanto, puedes ver esas páginas aparecer en las SERP aunque no quieras.
Arreglo: tienes que eliminar los enlaces que apuntan a esa página concreta y dirigirlos a una página similar en su lugar.
Para hacerlo, tienes que identificar sus enlaces internos realizando una auditoría SEO con una herramienta como Screaming Frog (gratis para webs de 500 URL) o Ahrefs Webmaster Tools (una alternativa gratuita mucho mejor) para identificar qué páginas enlazan a tus páginas bloqueadas.
Con Ahrefs, ve a Reportes > Páginas internas tras ejecutar una auditoría. Busca las páginas que bloqueaste a los bots y noindexaste y comprueba qué páginas enlazan a ellas en la columna N.º de Inlinks.
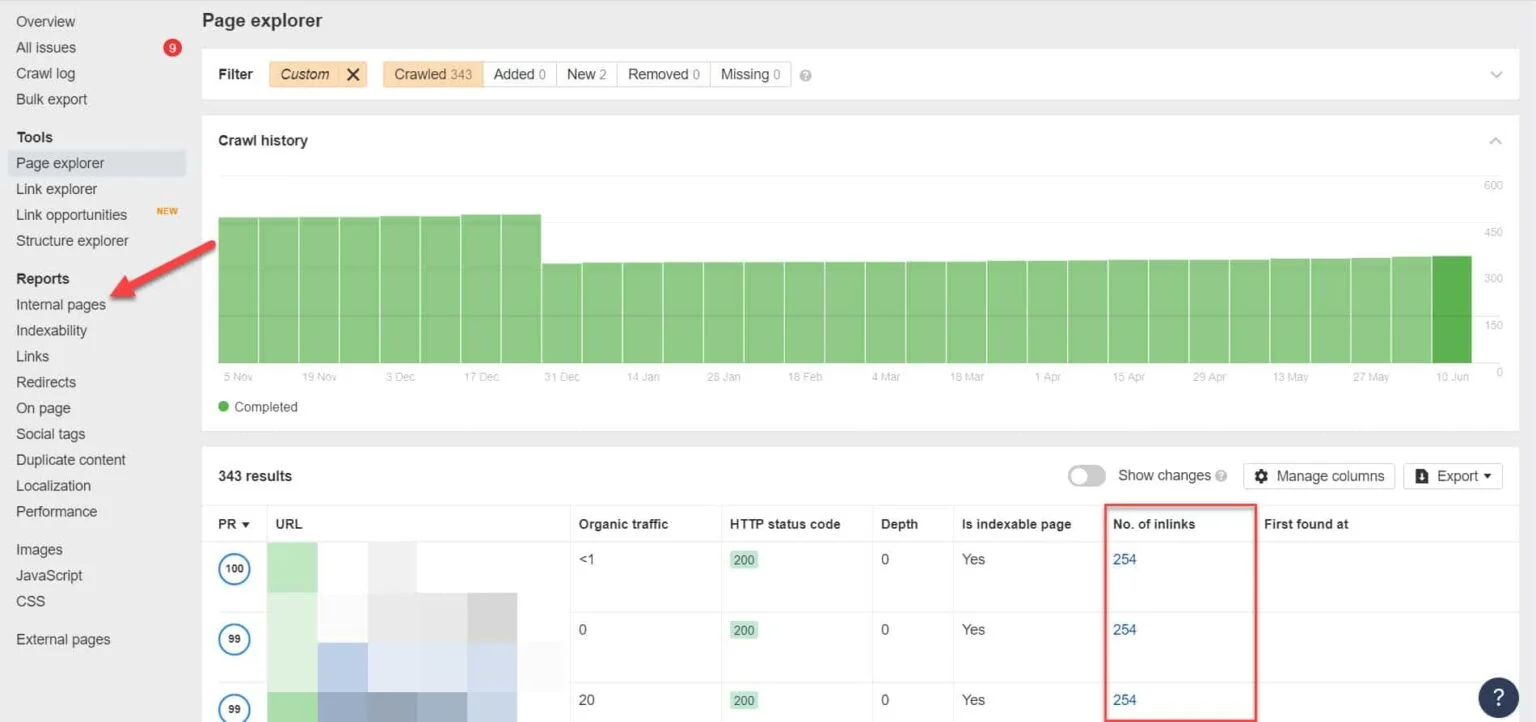
A partir de ahí, modifica los enlaces de esas páginas uno a uno. O puedes reemplazarlos por un enlace a tu página con etiqueta noindex.
Apuntar a una cadena de redirección
Si un enlace de tu sitio apunta a un flujo ininterrumpido de redirecciones, Googlebot dejará de pasar por cada enlace antes de encontrar la URL real de la página.
Esas cadenas de redirección también podrían causar problemas de contenido duplicado que podrían causar problemas SEO mayores con el tiempo. La única forma de resolverlo es identificar tu página preferida y canónica con la etiqueta canonical, para que Google sepa qué página de tantas debe rastrear e indexar.
Considera también que enlazar a una redirección en lugar de a la página canónica usa tu crawl budget. Si el enlace de redirección apunta a varias redirecciones, no puedes usar tu crawl budget en las páginas que importan en tu sitio. Cuando llegue a las páginas más importantes, Google no podrá rastrearlas e indexarlas correctamente tras un tiempo.
Arreglo: elimina los enlaces de redirección de tu sitio y enlaza a la página canónica en su lugar.
De nuevo con Ahrefs Webmaster Tools, puedes ver tus enlaces de redirección en la página Herramientas > Link Explorer. Luego filtra los resultados para que solo te muestren los enlaces de redirección dentro de tu sitio.
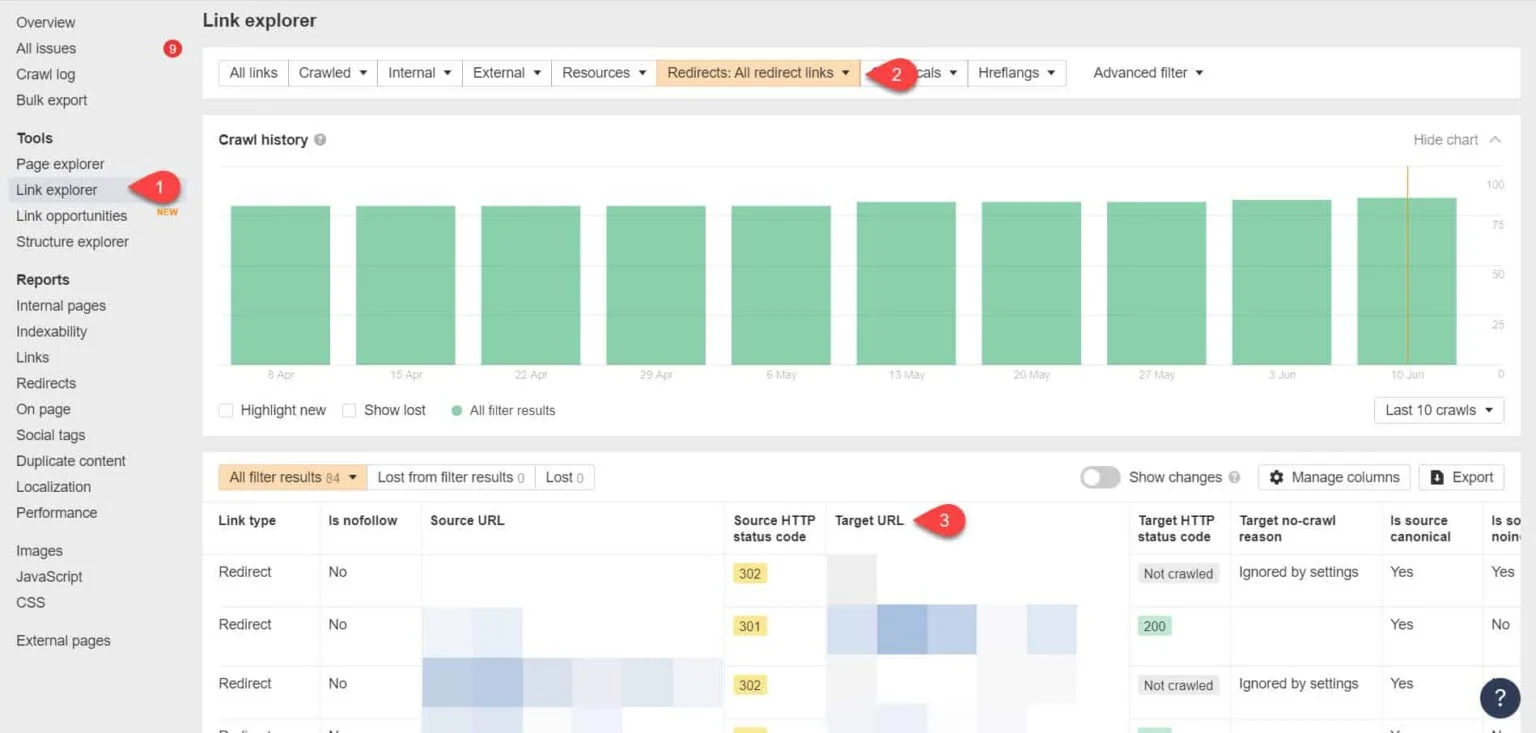
De los resultados, identifica los enlaces que forman una cadena de redirección sin fin. Luego rompe la cadena encontrando la página correcta a la que cada página enlazada a las redirecciones debería enlazar.
Qué hacer después de resolver este problema
Cuando hayas implementado las soluciones anteriores para las páginas importantes con el problema «indexado aunque bloqueado por Robots.txt», tienes que verificar los cambios para que Google Search Console pueda marcarlos como resueltos.
Volviendo al reporte de cobertura de índice en GSC, haz clic en los enlaces con el problema que has resuelto. En la siguiente pantalla, haz clic en el botón Validar corrección.
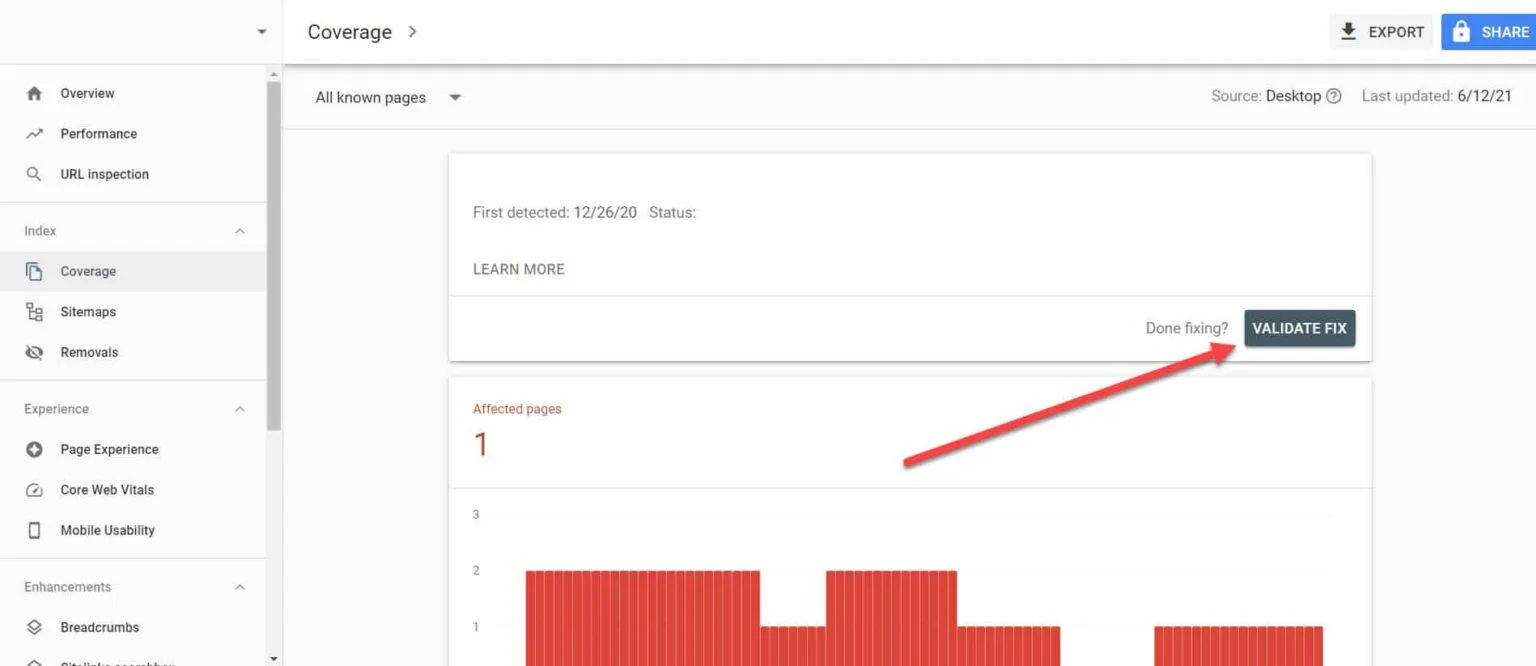
Eso pedirá a Google que verifique si la página ya no tiene el problema.
Conclusión
A diferencia de otros problemas descubiertos por Google Search Console, «indexado aunque bloqueado por robots.txt» puede parecer una gota en el océano. Sin embargo, esas gotas podrían acumularse en un torrente de problemas en todo tu sitio que le impedirá generar tráfico orgánico.
Siguiendo las instrucciones anteriores sobre cómo resolver el problema en tus páginas más importantes, puedes impedir que tu web pierda tráfico valioso optimizando tu sitio para que Google pueda rastrearlo e indexarlo correctamente.