Learn how you can apply Robots.txt optimization for better SEO performance. If you have pages on your website that Google indexed but can’t crawl, you will receive an “Indexed, Though Blocked by Robots.txt” message on your Google Search Console (GSC).
While Google can view these pages, it won’t show them as part of search engine results pages for their target keywords.
If this is the case, you will miss out the opportunity of getting organic traffic for these pages.
This is especially crucial for pages generating thousands of monthly organic visitors only to encounter this issue.
At this point, you probably have lots of questions about this error message. Why did you receive it? How did it happen? And, more importantly, how can you fix it and recover the traffic if this happened to a page that was already ranking well.
This post will answer all these questions and show your how to avoid this issue from happening on your site again.
How to Know if Your Site Has This Issue
Normally, you should receive an email from Google informing you of an “index coverage issue” on your site. Here’s what the email looks like:
The email won’t specify what the exact affected pages or URL are. You’ll have to log in to your Google Search Console to find out yourself.
If you didn’t receive an email, it’s best to still see it for yourself to make sure that your site is in tip-top shape.
Upon logging in to GSC, go to the Index Coverage Report by clicking on Coverage under Index. Then, on the next page, scroll down to see the problems being reported by GSC.
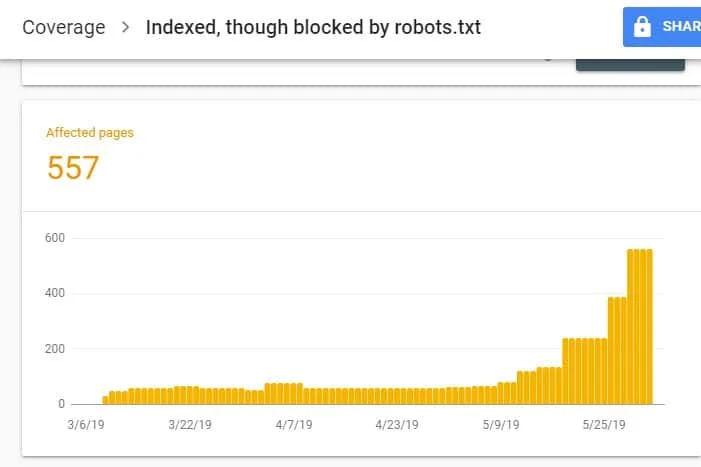
The “Indexed, Though Blocked by robots.txt” is labeled under “Valid with warning”. This means there’s nothing wrong with the URL per se, but search engines won’t show the page(s) on search engine results.
Why Does Your Site Have This Issue (and How to Fix)?
Before you start thinking of a solution, you must know first which pages need to be indexed andmust appear on search results.
It’s possible that the URLs that you see on GSC with the “Indexed, Though Blocked by robots.txt” issue aren’t meant to drive organic traffic to your site. For example, landing pages for your paid ad campaigns. Therefore, fixing the pages may not be worth your time and effort.
Below are reasons why some of your pages have this issue and whether or not you should fix them:
Disallow Rule on Your Robots.txt andNoindex Meta Tag in the Page’s HTML
The most common reason why this issue takes place is when you or someone managing your site enables the Disallow rule for that specific URL on your site’s robots.txt and added the noindex meta tag on the same URL.
First, site owners use robots.txt to inform search engine crawlers on how to treat your site URLs. In this case, you added the Disallow Rule on pages and folders of your site in your website’s robots.txt.
Here’s what you may see when you open your site’s robots.txt file:
User-agent: * Disallow: /
In the example above, this line of code prevents all web crawlers (*) from crawling your site pages (Disallow) include your homepage (/). As a result, all search engines will neither crawl nor index your site pages.
You can edit robots.txt to single out web crawlers (Googlebot, msnbot, magpie-crawler, etc.) and specify which page or pages you don’t want the crawlers to touch (/page1, /page2, /page3, etc.).
However, if you don’t have root access to your server, you can prevent search engine bots from indexing your site pages using the noindex tag.
This method has the same effect as the disallow rule on robots.txt. However, instead of listing down the different pages and folders on your site in a robots.txt file that you want to prevent from appearing on SERPs, you have to enter the noindex meta tag on each page of your site that you don’t want to appear in search results.
This is a much more time-consuming process than the previous method, but it gives you more granular control as to which URL to block. This also means there’s a lower margin for error on your part.
Fix: Again, the issue in GSC arises when pages on your site have a disallow rule on robots.txt file and a noindex tag.
In order for search engines to know whether to index a page or not, it should be able to crawl it from your site. But if you prevent search engines from doing so through your robots.txt, it wouldn’t know what to do with that page.
By using robots.txt and the noindex tag to complement and not compete against each other, your site will have much clearer and more direct rules for search engine bots to follow when treating its pages.
To do this, you must edit your robots.txt file. For WordPress site owners, using SEO plugins with a robots.txt editor like Yoast SEO or Rank Math is the most convenient.
![]()
If the robots.txt is not writable on your end, you must reach out to your hosting provider to make permission changes to your files and folders.
Another way is to log in to your FTP client or the File Manager of your hosting provider. This is the preferred method among developers because they have complete control over how to edit the file among other things.
Wrong URL Format
URLs in your site that aren’t really “pages” in the strictest sense may receive the “Indexed, Though Blocked by robots.txt” message.
For instance, https://example.com?s=what+is+seo is a page on a site that shows the search results for the query “what is seo.” This URL is prevalent among WordPress sites where the search feature is enabled site-wide.
Fix: Normally, there is no need to address this issue, assuming that the URL is harmless and isn’t profoundly affecting your search traffic.
Pages You Don’t Want Indexed Have Internal Links
Even if you have noindex tag on the page you don’t want indexed, Google may treat them as suggestions instead of rules. This is evident when you link to pages with either noindex directive or disallow rule on pages on your site that search engines crawl and index.
Therefore, you may see these pages appearing on SERPs even if you don’t want to.
Fix: You must remove the links pointing to this particular page and lead them to a similar page instead.
To do this, you must identify its internal links by running an SEO audit using a tool like Screaming Frog (free for websites with 500 URLs) or Ahrefs Webmaster Tools (a much better free alternative) to identify which pages link to your blocked pages.
Using Ahrefs, go to Reports > Internal pages after running an audit. Find the pages you have blocked from web crawlers and noindexed and see which pages link to them on the No. of Inlinks column.
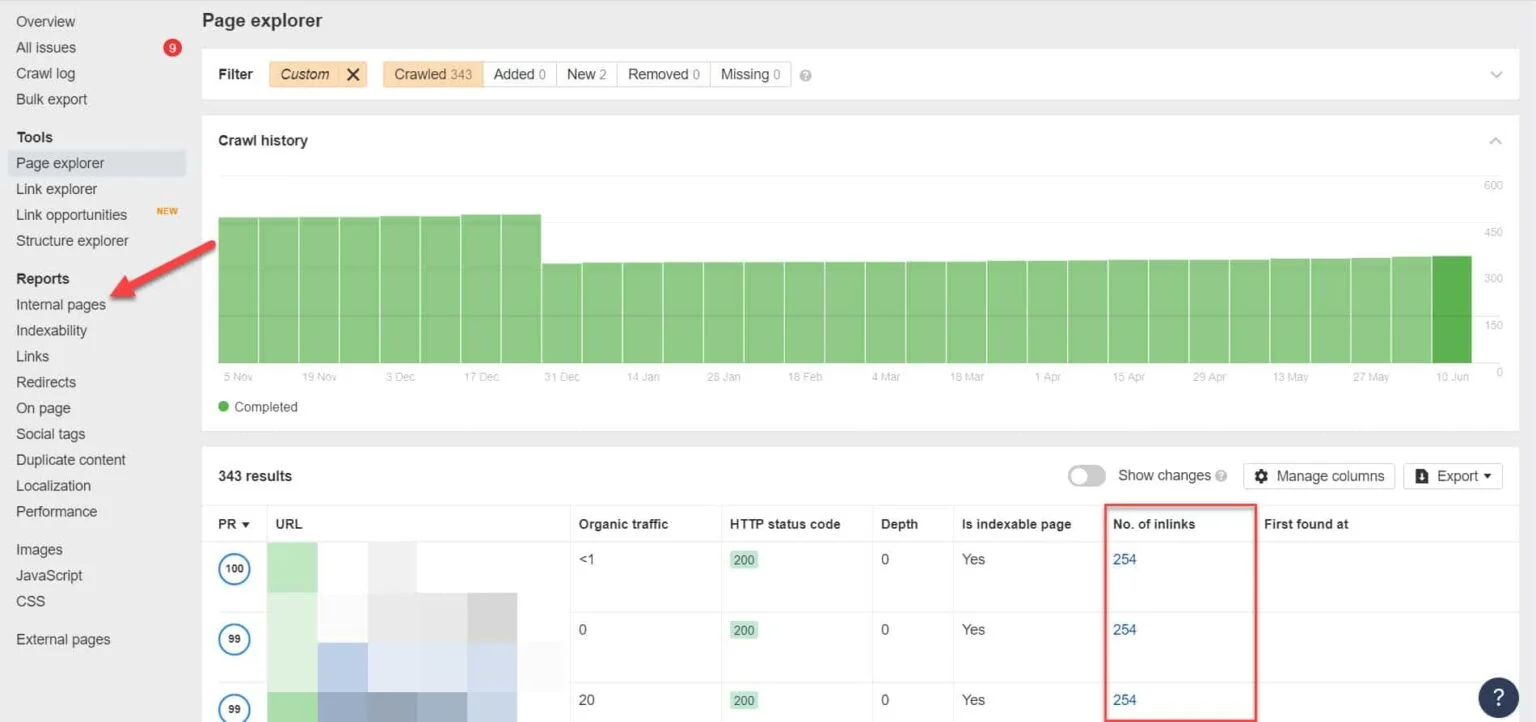
From here, edit the links from these pages one at a time. Or you can replace them with a link to your page with a noindex tag.
Pointing to a Redirect Chain
If a link on your site points to an endless stream of redirects, then Googlebot will stop passing through each link before it finds the actual URL to the page.
These redirect chains could also cause duplicated content issues that could cause bigger SEO problems down the line. The only way to resolve this is by identifying your preferred and canonical page with the canonical tag so Google knows which page among many it should crawl and index.
Also, consider that linking to redirect instead of the canonical page use up your crawl budget. If the redirect link points to multiple redirects, you don’t get to use your crawl budget on pages that matter in your site. By the time it gets to the most important pages, Google won’t be able to properly crawl and index them after a period.
Fix: Eliminate the redirect links from your site and link to the canonical page instead.
Using Ahrefs Webmaster Tools again, you can view your redirect links on the Tools > Link Explorer page. Then filter the results to only show you redirect links in your site.
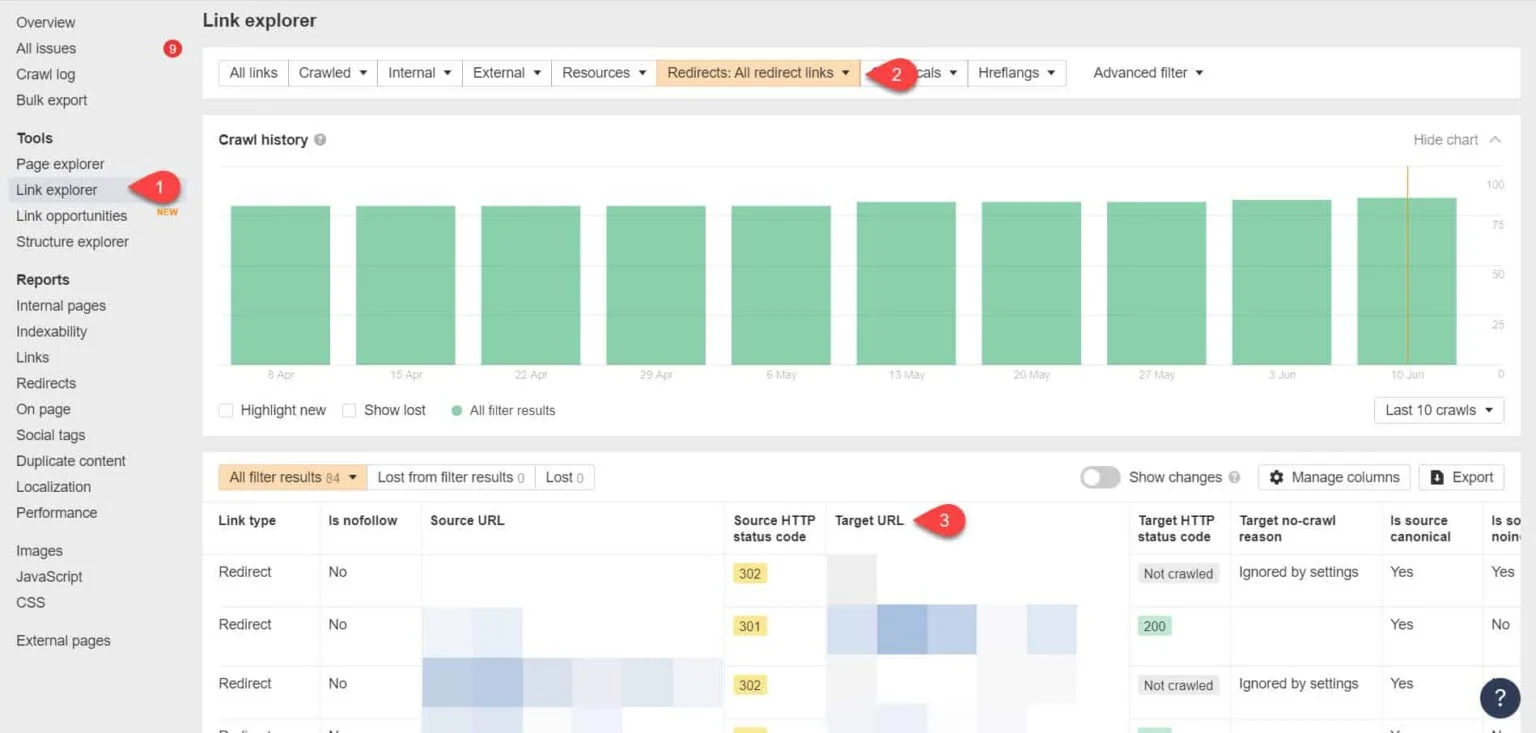
From the results, identify which links form an endless redirect chain. Then break the chain by finding the correct page that each page linking to the redirects should link to.
What to Do After Fixing This Issue
Once you’ve implemented the solutions above to important pages with the “Indexed, Though Blocked by Robots.txt” issue, you need to verify the changes so Google Search Console can mark them as resolved.
Going back to the Index Coverage Report in GSC, click on the links with this issue that you’ve fixed. On the next screen, click on the Validate Fix button.
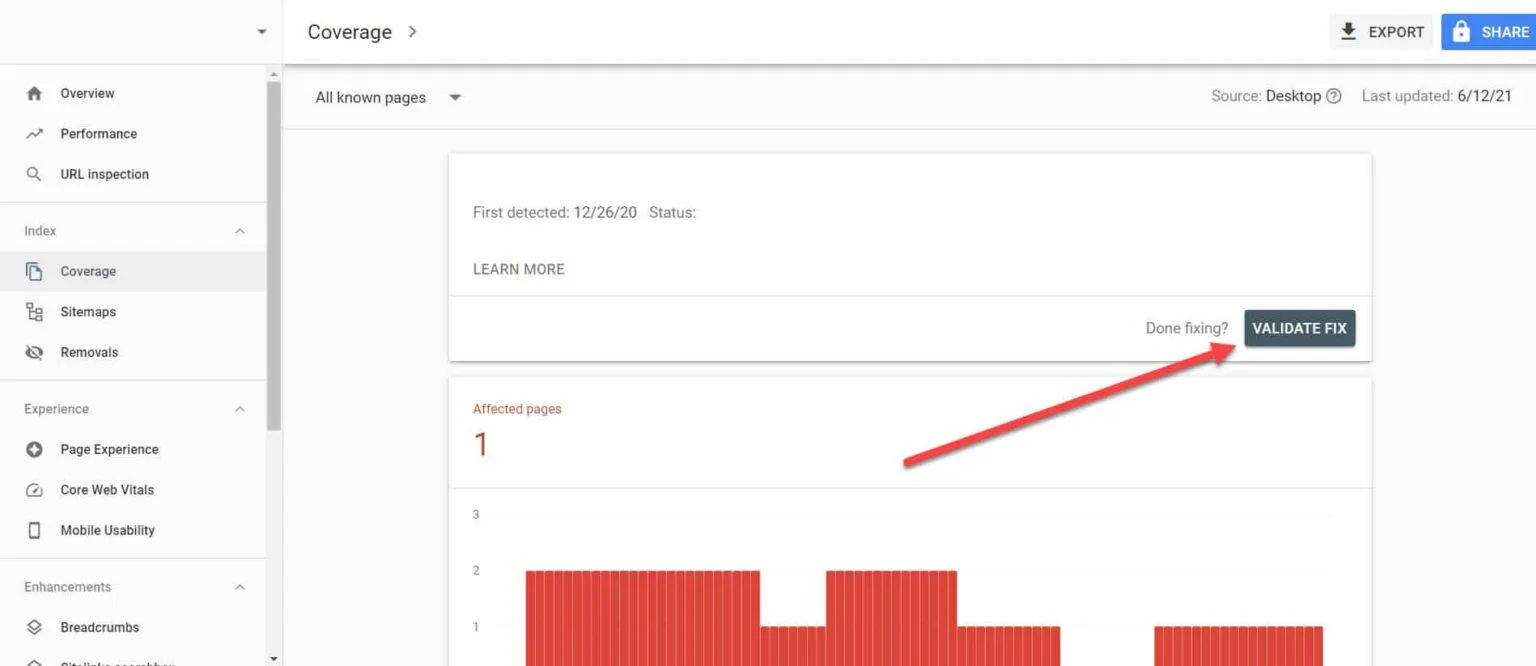
This will request Google to verify if the page no longer has the issue.
Conclusion
Unlike other issues uncovered by Google Search Console, “Indexed, Though Blocked by robots.txt” may seem like a drop in the bucket. However, these drops could accumulate into a torrent of problems to your entire site that will prevent it from generating organic traffic.
By following the guidelines above on how to resolve the issue on your most important pages, you can prevent your website from losing valuable traffic by optimizing your website for Google to crawl and index properly.